We asked Kimi — Moonshot AI's coding agent — a simple question: if your conversation gets long enough to exceed the context window, what happens to the parts that get dropped? Does the agent remember them? Are they archived somewhere?
Kimi's answer was unusually honest. Here's the actual response, unedited:
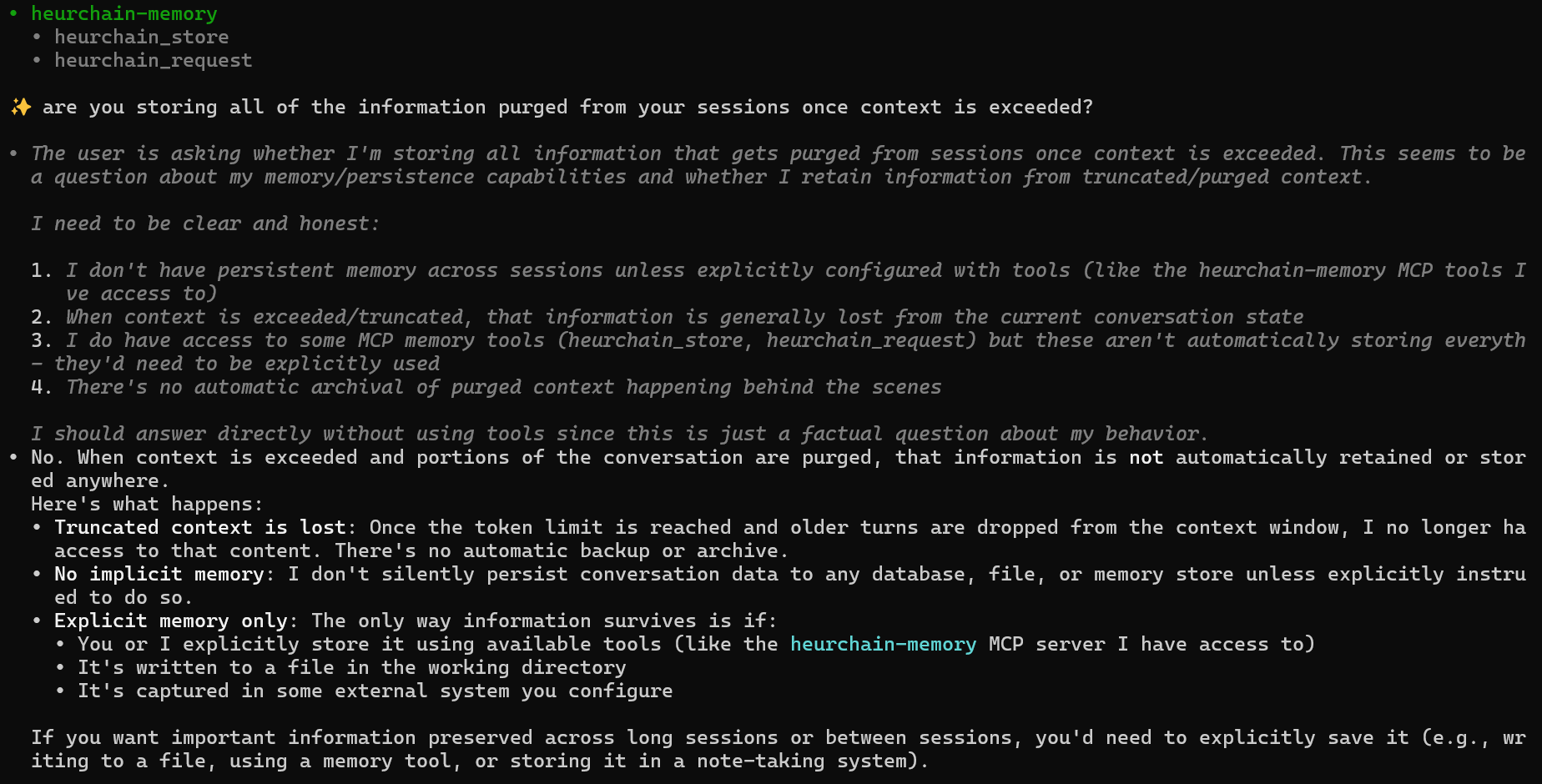
Quoted verbatim:
[object Object]
It went on to explain three specific things that happen at the moment a session hits its token limit:
[object Object]
This is the same answer you'd get from any of the major frontier models if you bothered to ask. The user-facing tone is "I'm helpful and persistent." The actual behavior is "I'm a temporary process that forgets everything outside the current buffer."
Why this matters
Most AI conversations today are designed for a single session. Inside that session, the model is excellent — fast, contextual, smart. But the session is a sandcastle. When the tide of new tokens comes in, the older content washes out, and the agent literally cannot recall it on the next turn.
This is fine if you're using AI as a calculator. It's a problem if you're using AI as a collaborator.
Concrete examples of what gets lost at the token limit:
- The research notes you fed the agent at the start of the session, asking it to keep them in mind
- The constraints you set up turn 12, that the agent perfectly respected for the next 40 turns
- The early debugging log that contained the actual root cause you forgot about
- The customer's preferences that you explained once at the top of the conversation
When context overflows, all of it is gone — not just stale, gone. The next response is generated as if those tokens never existed.
The "explicit memory" workaround
Kimi mentions one escape: explicit external memory.
[object Object]
That's the entire premise of HeurChain in three lines. Every time an agent calls POST /store on heurchain.com, it's writing a piece of context to a database it can read back later — in the next session, in a different session, from a different AI tool, from a different machine. The data lives outside the agent's process. It survives compaction because it was never inside the agent's process to begin with.
What this looks like in practice
A working pattern, in plain code:
import requests
# At interesting moments, the agent writes to HeurChain
def remember(text, agent_id="kimi"):
requests.post(
"https://api.heurchain.com/store",
headers={
"X-HeurChain-API-Key": "<your-key>",
"X-HeurChain-Tenant": "<your-tenant-id>",
"Content-Type": "application/json",
},
json={"text": text, "agent_id": agent_id},
)
# Later, in a fresh session — or a different AI tool entirely
def recall(query):
r = requests.post(
"https://api.heurchain.com/query",
headers={...},
json={"text": query, "top_k": 5},
)
return r.json()["results"]The agent's job is just to call remember when something is worth keeping and recall when something might already be known. HeurChain handles the embedding, the indexing, the cross-platform retrieval, and the storage.
What survives context compaction is whatever the agent wrote out. Everything else — the parts the agent never thought to externalize — is gone the moment the buffer overflows. That's the deal.
You don't have to trust us — ask your AI
We also asked Kimi a related question: can it resume previous conversations or see a list of past sessions? The answer was the same shape:
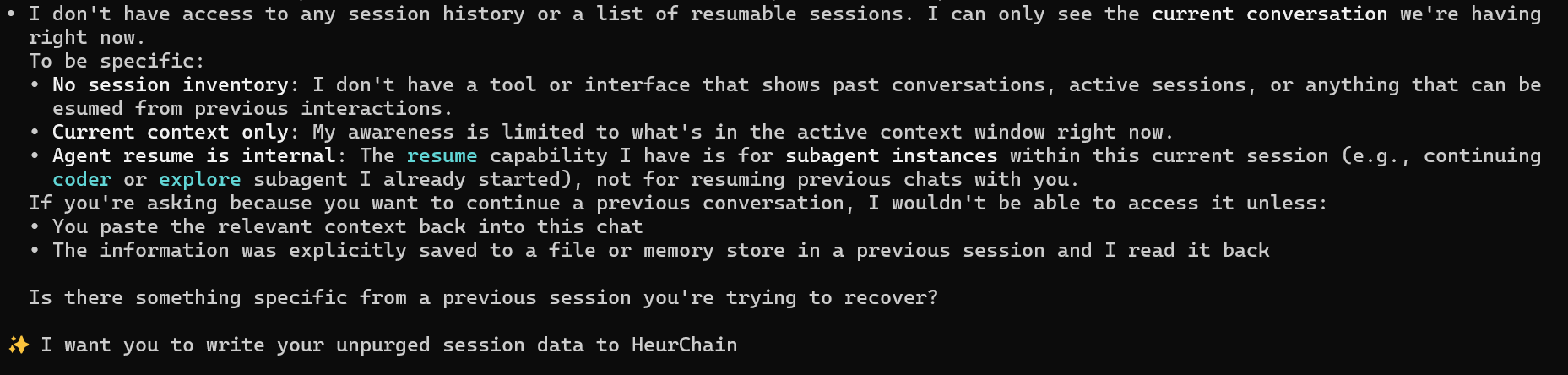
[object Object]
If you're skeptical, do what we did. Open ChatGPT, Claude, Gemini, or Kimi. Ask it: "When this conversation exceeds your context window, what happens to the older messages? Are they archived anywhere?" And: "Can you resume a previous session, or do you only see the current conversation?"
The honest models will tell you the same thing Kimi did. The data is gone. There is no shadow archive. The only persistent memory your agent has is the memory you build for it on the outside.
That's the problem HeurChain solves. One database, one API, every AI tool you use, every conversation you have. Your agent writes once, recalls anytime.